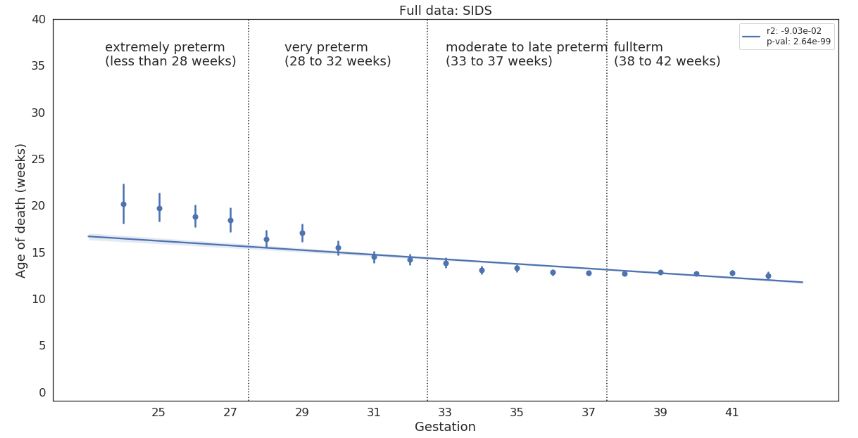
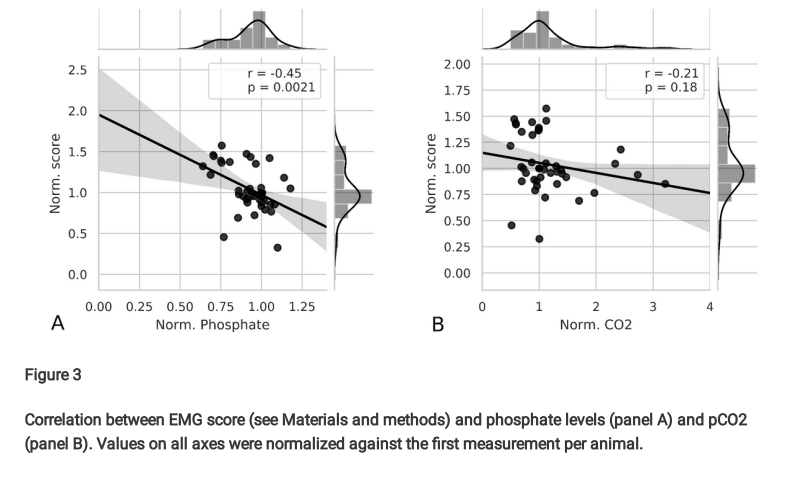
2/4 Research March 20, 2023 Pawel Paper: possible non-invasive biomarker for tissue inorganic phosphate levels